Location-Based Intrinsic Reward in RL
Project Overview
This project explored the effectiveness of intrinsic reward systems in reinforcement learning. I experimented with a hummingbird agent in a Unity virtual environment that was trained to collect nectar from flowers. The standard approach only rewards the agent for accomplishing the primary goal (an extrinsic reward system), but I hypothesized that providing additional rewards for behaviors that might lead to the goal could improve training efficiency and performance.
Key Components
Virtual Environment Setup
I implemented a virtual environment in Unity where a hummingbird agent navigated to collect nectar from flowers. The agent received observational inputs including its position and orientation in 3D space, as well as a vector between the tip of its beak and the closest flower's nectar hitbox. The baseline model used an extrinsic reward system, where the agent was only rewarded for successfully collecting nectar by positioning its beak inside a flower's nectar hitbox.
Location-Based Intrinsic Reward System


I designed a novel location-based intrinsic reward system that supplemented the primary goal with additional rewards for productive exploration. This involved creating triangular prism-shaped triggers arranged in a circular "pizza slice" pattern at the same Z-level as the flowers. When the agent entered these trigger zones, it received a small reward, and the trigger was then disabled for the remainder of that training episode.
The key innovation was rewarding the agent for exploring the Z-level where flowers were located, even before directly interacting with the flowers themselves. This encouraged the agent to stay in productive areas and explore within those areas, potentially discovering more efficient paths to nectar collection.
Training and Evaluation
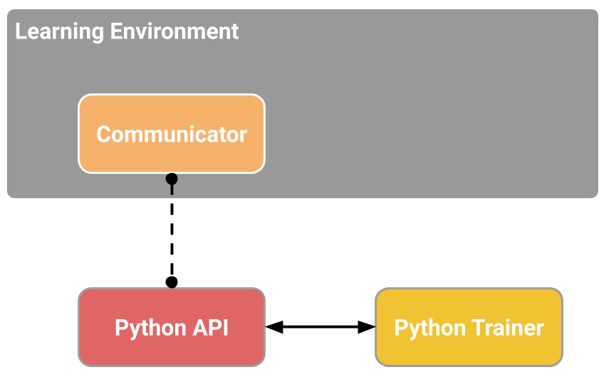
I trained both the standard extrinsic-only reward model and the enhanced intrinsic+extrinsic reward model using the Unity ML-Agents framework with a Python backend. The training process was managed through an Anaconda environment, and a custom configuration file specified the neural network architecture and hyperparameters. TensorBoard was used to visualize and compare performance metrics between the two approaches over time.
Technologies Used
- Unity game engine for environment creation
- Unity ML-Agents package for reinforcement learning implementation
- Python API for neural network interface
- C# for Unity scripts and trigger functionality
- Anaconda for Python environment management
- TensorBoard for visualizing training metrics
Results
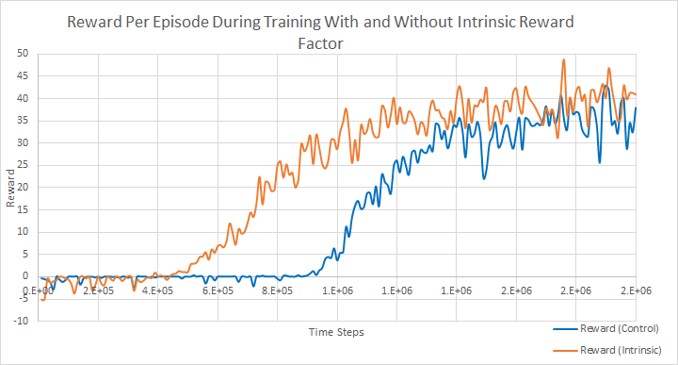
The location-based intrinsic reward system demonstrated faster convergence to optimal behavior compared to the standard extrinsic-only reward approach. Agents trained with the combined reward system showed more efficient exploration patterns, spending more time in areas with potential rewards and less time in unproductive regions. This project highlights the importance of reward shaping in reinforcement learning and demonstrates how well-designed intrinsic rewards can guide agents toward desirable behaviors even before they achieve the primary goal.